LLaMa in a Box! Running GenerativeAI out of a Raspberry Pi 4
Your own Genie (ChatGPT) in a bottle :-)


We've at this point, all heard of AI, GenerativeAI and LLMs - the idea here is to try and run a large language-based model generative Chat experience (similar to #ChatGPT) out of the least powerful portable device I can find - in this case, the Raspberry Pi 4b
Just for reference, while there are multiple ways of doing this, I wanted a model that would be
portable - hence, the install footprint was small enough to carry around
did not need access to the Internet for it to work!
Which immediately threw out #OpenAI's API-based models
Meta (God, how I hate that name) or Facebook recently came out with their #LLaMa 2 language model that looked perfect till you came across the size we had to deal with
You can find the documentation below
LLaMA 2 - Meta's Language Model
Request form for LLaMa models and libraries
While researching, I came across Sosaka works - essentially, they have been able to reduce the size of the language model from 7tb to 4 gigs, which meant that with some luck and trial and error, we might just be able to run the language models on a laptop, or in my case my Raspberry Cluster :-)
So let's get building. Hardware needed - clustered Raspberry Pi or even a single Raspberry Pi 4b (more memory and CPU cores, the better) and external storage - I am using a SanDisk® USB 3.2, 128 GB pen drive and a SanDisk® SDCard 32 gb for the OS
First thing is to install the base OS. I used the Raspberry Pi Imager to install a Ubuntu server headless install
Update the install and install essential build tools
sudo apt-get update
sudo apt install -y software-properties-common
sudo apt install -y build-essential



Next steps, mount the drives and download the model file from here or from Sosaka's link here


Clone the repo using the command below
sudo git clone https://github.com/antimatter15/alpaca.cpp
Note: cd into the directory you need the repo and files to reside in. For me, it was the USB 3.2 Sandisk Pen/Thumb drives

Enter the directory alpaca and use the make command



Move the language model to the alpaca directory
sudo mv ../ggml-alpaca-7b-q4.bin .

Start the chat and wait for the prompt to come up and fire off a couple of random questions :-)
sudo ./chat

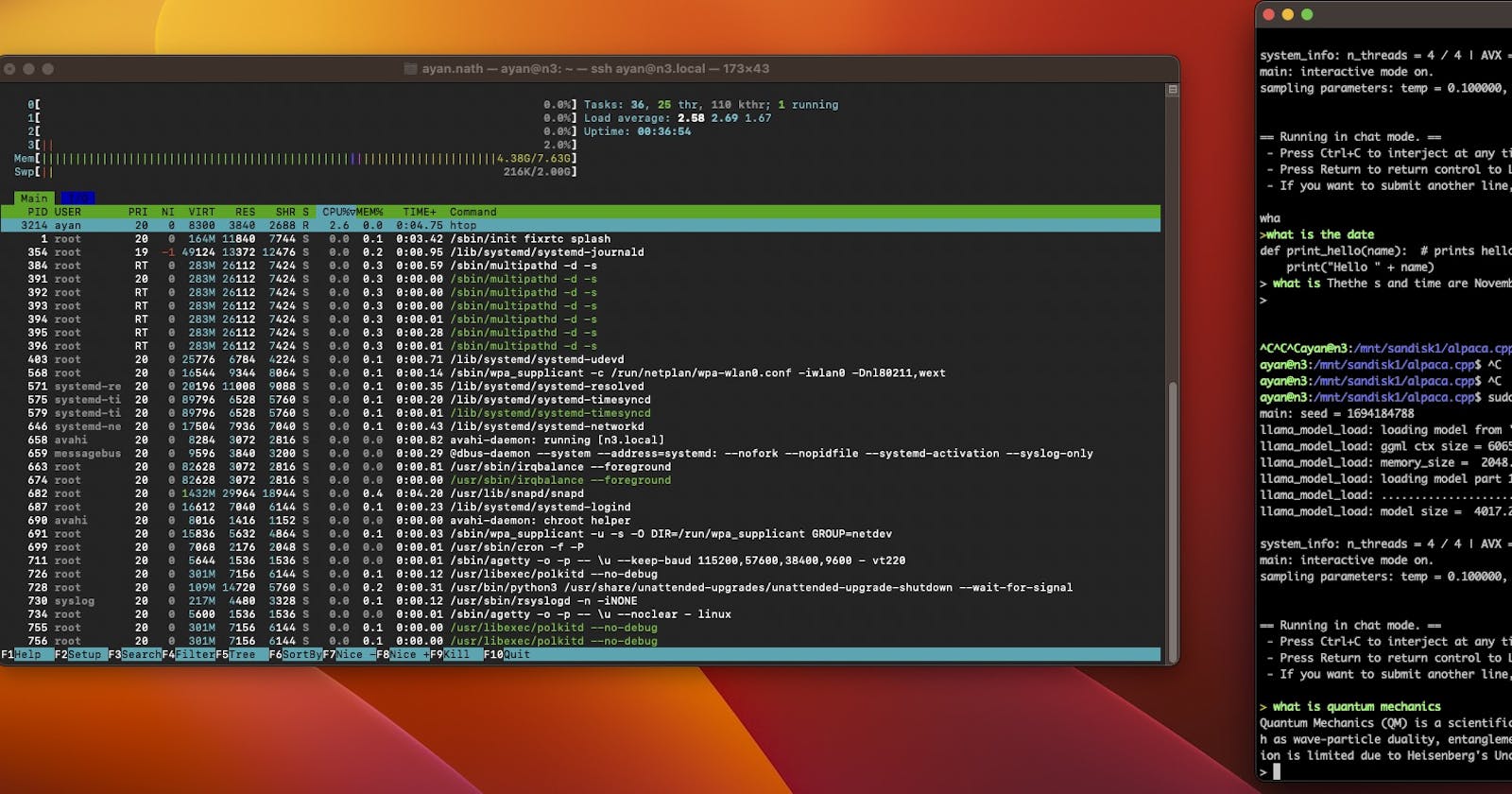
Open a parallel Putty/terminal and check the htop :-)


That's pretty wild usage :-) But then performance was never the goal!

Points to note:
As seen on htop, each run of the chat creates four processes that absolutely hammers the single Raspberry. It's better if three nodes are clustered
Chat responses are sluggish and will depend on the speed of your cards/USB drives/External drives that the language models are running from
This actually has voice output if drives and speakers are connected and sound is enabled - which sounds a lot better than the chat mode :-)
Happy tinkering! Let me know this works for you :-)